tl;dr: State of HTML 2025 survey is now open!
Take it now
Mamma mia, here we go again!
About two weeks ago, I announced that I was back leading this year’s State of HTML 2025 survey, after a one year hiatus.
We are grateful for all the suggestions that poured in, they were immensely helpful in shaping the survey.
After two weeks of hard work from a small team spanning three continents, we are finally ready to launch!
I would urge each and every one of you that works with the web platform to fill out this survey.
It’s a unique opportunity to have your voice heard in the browser vendors’ decision-making process.
Survey results are used by browsers to prioritize roadmaps — the reason Google is funding this.
The results from State of … surveys directly feed into prioritization for next year’s Interop project.
Time spent thoughtfully filling them out is an investment that can come back to you tenfold
in the form of seeing features you care about implemented, browser incompatibilities being prioritized, and gaps in the platform being addressed.
In addition to browsers, several standards groups are also using the results for prioritization and decision-making.
Additionally, you get to learn about new and upcoming features you may have missed,
and get a personalized, sharable score at the end to see how you compare to other respondents!
While the survey will be open for about a month,
responses entered within the first two weeks (until end of July) will have a much higher impact on the Web,
as preliminary data will be directly used to inform Interop 2026.
We spent a lot of time thinking about which features we are asking about and why.
As a result, we added 35 new features, and removed 18 existing ones to make room.
This is probably one of the hardest parts of the process, as we had to make some tough decisions.
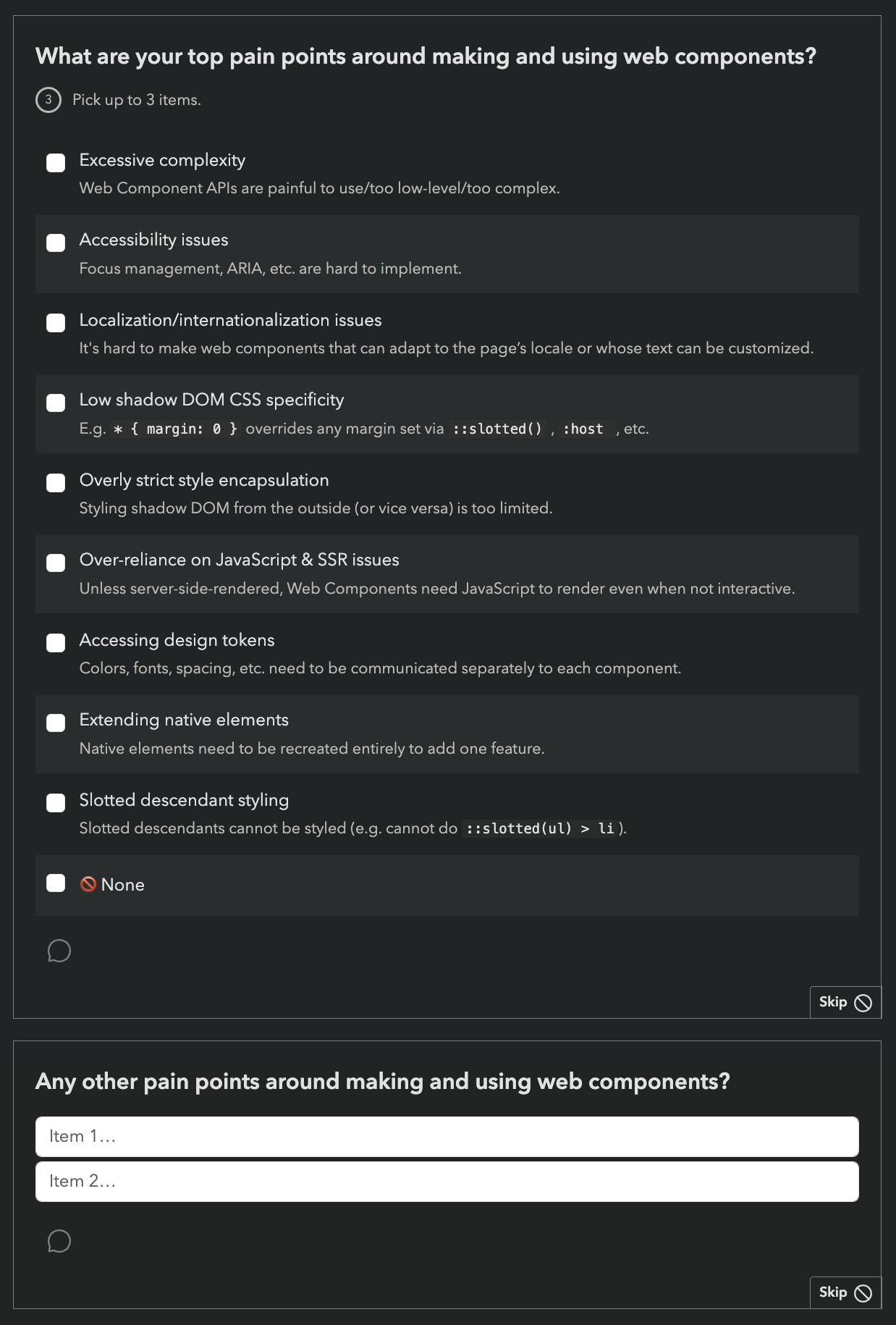
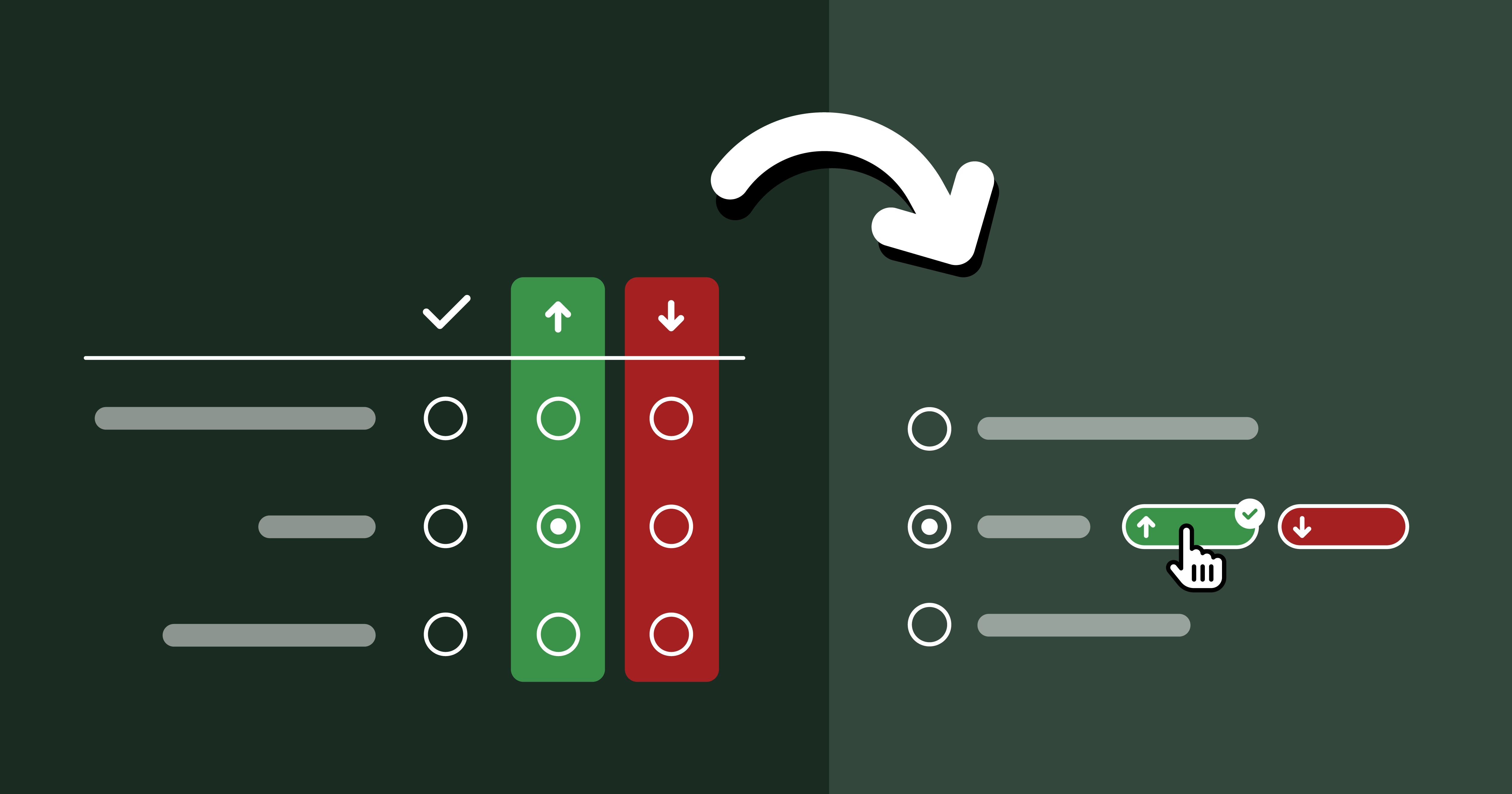
We are also using the Web Components section to pilot a new format for pain points questions,
consisting of a multiple choice question with common pain points,
followed by the usual free form text list:
While this increases the number of questions,
we are hoping it will reduce survey fatigue by allowing participants to skip the freeform question more frequently (or spend less time on it) if most of their pain points have already been covered by the multiple choice question.
Last but not least, we introduced browser support icons for each feature, per popular request:
Absolutely! Do not worry about filling it out perfectly in one go.
If you create an account, you can edit your responses for the whole period the survey is open, and even fill it out across multiple devices,
e.g. start on your phone, then fill out some on your desktop, etc.
Even if you’re filling it out anonymously, you can still edit responses on your device for some time,
so you can have it open in a browser tab and revisit it periodically.
For the same reason there are JS APIs in the HTML standard:
many JS APIs are intrinsically related to HTML.
We mainly included JS APIs that are in some way related to HTML, such as:
APIs used to manipulate HTML dynamically (DOM, interactivity, etc.)
Web Components APIs, used to create custom HTML elements
PWA features, including APIs used to access underlying system capabilities (OS capabilities, device capabilities, etc.)
The only two exceptions to this are two Intl APIs,
which were mainly included because we wanted to get participants thinking about any localization/internationalization pain points they may have.
However, if you don’t write any JS, we absolutely still want to hear from you!
In fact, I would encourage you even more strongly to fill out the survey,
as people who don’t write JS are very underrepresented in these surveys.
All questions are optional, so you can just skip any JS-related questions.
There is also a question at the end, where you can select that you only write HTML/CSS:
While proposals with no browser support are not good candidates for immediate prioritization by browsers,
their context chips give browser vendors and standards groups invaluable insight into what matters to developers,
which also drives prioritization decisions.
However, we heard you loud and clear: when mature and early stage features are mixed together, you felt bait-and-switched.
So this year, we are including icons to summarize browser support of each feature we ask about:
We are hoping this will also help prevent cases where participants confuse a new feature they have never heard of, with a more established feature they are familiar with.
Absolutely not! Localization has been an integral part of these surveys since the beginning.
Fun fact: None of the people working on these surveys is a native English speaker.
However, since translations are a community effort, they are not necessarily complete, especially in the beginning.
If you are a native speaker of a language that is not yet complete, please consider helping out!
Two years ago, I was funded by Google to design the inaugural State of HTML survey.
While I had led State of … surveys before (also graciously sponsored by Google), that was by far the most intense, as 0→1 projects often are.
In addition to the research, content, and analysis work that goes into every State of … survey,
the unique challenges it presented were a forcing function for finally tackling some longstanding UX issues with these surveys.
As a result, we pioneered new survey interaction UIs, and validated them via usability testing.
This work did not just affect State of HTML, but had ripple effects on all subsequent State of … surveys.
The results made it all worth it.
Turnout was the highest ever for a new Devographics [1] survey: 21 thousand participants, which remains a record high for State of HTML.
The survey findings heavily influenced Interop 2024 (hello Popover API and Declarative Shadow DOM!) and helped prioritize several other initiatives, such as stylable selects.
Despite lower 2024 participation, the survey still significantly influenced Interop 2025;
notably, View transitions was added after being prominent in the survey for two years in a row.
This is the goal of these surveys: to drive meaningful change in the web platform.
Sure, getting a shareable score about what you know and seeing how you compare to the rest of the industry is fun, but the reason browser vendors pour thousands of dollars into funding these surveys is because they provide unique vendor-neutral insights into developer pain points and priorities, which helps them make better decisions about what to work on.
And this ultimately helps you: by getting your voice heard, you can directly influence the tools you work with.
It’s a win-win: developers get better tools, and browser vendors get better roadmaps.
Last year, I was too busy to take the lead again.
Wrapping up my PhD and starting a new job immediately after, there was no time to breathe, let alone lead a survey.
I’m happy to be returning to it this year, but my joy is bittersweet.
When I was first asked to lead this year’s survey a few months ago,
I was still too busy to take it on.
Someone else from the community accepted the role — someone incredibly knowledgeable and talented who would have done a fantastic job.
But they live in the Middle East, and as the war escalated, their safety and their family’s well-being were directly impacted.
Understandably, leading a developer survey became the least of their concerns.
In the meantime, I made a few decisions that opened up some availability, and I was able to step in at the last minute.
It’s a sobering reminder that events which feel far away can hit close to home — shaping not just headlines, but the work and lives of people we know.
A big part of these surveys is “feature questions”: respondents are presented with a series of web platform features,
and asked about their familiarity and sentiment towards them.
At the end, they get a score based on how many they were familiar with that they can share with others,
and browser vendors and standards groups get signal on which upcoming features to prioritize or improve.
You can see which features were included in last year’s survey here or in [2] the table below.
I believe that co-designing these surveys with the community is the best way to avoid blind spots.
While the timeline is tighter than usual this year (the survey is launching later this month!), there is still a little time to ask:
👉🏼 Which upcoming HTML features or Web APIs are currently on your radar? 👈🏼
What does “on your radar” mean? Features you’re excited about and would love to see progress on.
Why focus on upcoming features?
The best candidates for these surveys are features that are mature enough to be fleshed out (at least a mature proposal, ideally a spec and WPT tests),
but not so mature they have already been implemented in every browser.
These are the features for which a survey such as this can drive meaningful impact.
If it’s so early for a feature that it’s not yet fleshed out, it’s hard to make progress via initiatives such as Interop.
Interest is still useful signal to help prioritize work on fleshing it out, but it’s a bit of a longer game.
And for features that are already implemented everywhere, the only thing that can improve things further is passage of time
— a problem for which I unfortunately have no solution (yet).
Obviously we’re looking at all the usual suspects already,
and initiatives such as webstatus.dev
and Web platform features explorer provide a treasure trove of data which makes this task infinitely easier than it used to be.
But this kind of preliminary signal is also useful for filtering and prioritization — to give you a sense, my list of candidate new features to ask about already has 57 items (!).
Given that State of HTML 2024 asked about 49 features, that will need some very heavy pruning.
While the title is “State of HTML”,
anything that wouldn’t fit better in State of CSS or State of JS is fair game.
This includes topics such as accessibility, browser APIs, web components, templating, static site generation, media formats, and more.
This may seem strange at first, but is no different than how the HTML specification itself covers a lot more than just HTML markup.
Any way to reach me works fine.
You can post in the comments here (preferred),
or reply on
BlueSky,
Mastodon,
Threads,
LinkedIn, or
Twitter.
Make sure to check the other replies first, and 👍 those with features you care about.
Looking forward to your ideas and comments!
Devographics is the company behind “State of …” surveys. ↩︎
As an Easter egg, this widget is just a <details> element with custom CSS.
Inspect it to see how it works!
It works best in Chrome and Safari, as they fully support ::details-content.
Chrome also supports calc-size(), which enables a nice animation, while the interaction in Safari is more abrupt.
In terms of a11y, the summary gets spoken out as a regular <summary> element, with “Show more” or “Show less” at the end of its content.
It seems ok-ish to me, but I’d love to hear from those with more expertise in this area. ↩︎
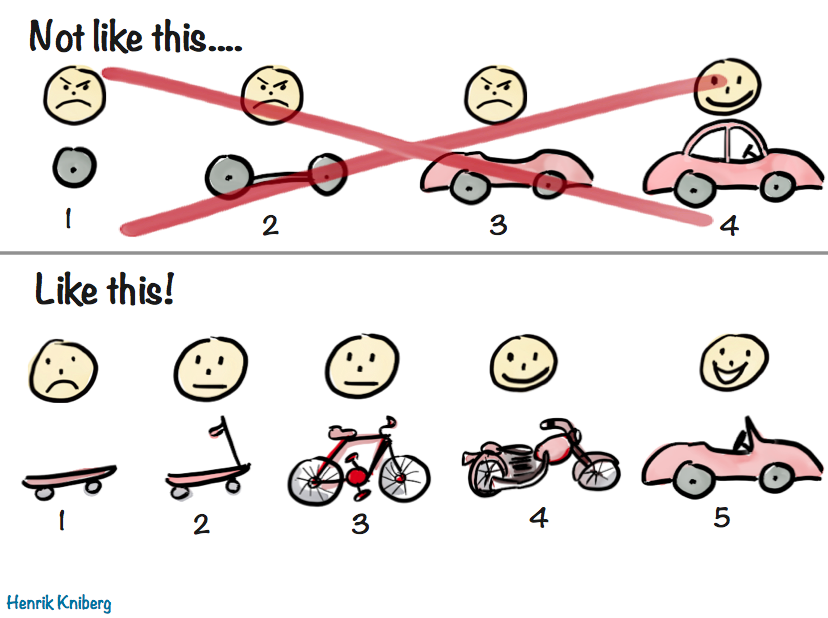
Many teams start with the MVP. But what if the key to shipping great products wasn’t starting small — but starting big? Could great products start at the finish line?
You may be familiar with this wonderful illustration and accompanying
blog post by Henrik Kniberg about good MVPs:
It’s a very visual way to illustrate the age-old concept that
that a good MVP is not the one developed in isolation over months or years,
grounded on assumptions about user needs and goals,
but one that delivers value to users as early as possible,
so that future iterations can take advantage of the lessons learned from real users.
I love Henrik’s metaphor so much, I have been using a similar system to flesh out product requirements and shipping goals, especially early on.
It can be immediately understood by anyone who has seen Henrik’s illustration,
and I find it can be a lot more pragmatic and flexible than the usual simple two tiered system (core requirements and stretch goals).
Additionally, I find this fits nicely into a fixed time, variable scope development process,
such as Shape Up.
🛹 The Skateboard aka the Pessimist’s MVP
What is the absolute minimum we can ship, if need be?
Utilitarian, bare-bones, and somewhat embarrassing, but shippable — barely.
Anything that can be flintstoned gets flintstoned.
🛴 The Scooter aka the Realist’s MVP
The minimum product that delivers value. Usable, but no frills. This is the target.
🚲 The Bicycle aka the Optimist’s MVP
Stretch goals — UX polish, “sprinkles of delight”, nonessential but high I/E features.
Great if we get here, fine if we don’t.
🏍️ The Motorcycle
Post-launch highest priority items.
🚗 The Car
Our ultimate vision, taking current constraints into account.
🏎️ The Hovercar aka the North Star UI
The ideal experience — unconstrained by time, resources, or backwards compatibility.
Unlikely to ship, but a guiding light for all of the above.
Please note that the concept of a North Star UI has no relation to the North Star Metric.
While both serve as a guiding light for product decisions, and both are important,
the North Star UI guides you in designing the product,
whereas the North Star Metric is about evaluating success.
To avoid confusion, I’ll refer to it as “North Star UI”, although it’s not about the UI per se, but the product vision on a deeper level.
The first three stages are much more concrete and pragmatic, as they directly affect what is being worked on.
The more we go down the list, the less fleshed out specs are, as they need to allow room for customer input.
This also allows us to outline future vision, without having to invest in it prematurely.
The most controversial of these is the last one: the hovercar, i.e. the North Star UI.
It is the very antithesis of the MVP.
The MVP describes what we can ship ASAP,
whereas the North Star describes the most idealized goal, one we may never be able to ship.
It is easy to dismiss that as a waste of time, a purely academic exercise.
“We’re all about shipping. Why would we spend time on something that may not even be feasible?” I hear you cry in Agile.
Stay with me for a moment, and please try to keep an open mind.
Paradoxical as it may sound, fleshing out your North Star can actually save you time.
How? Start counting.
At its core, this framework is about breaking down tough product design problems into three more manageable components:
North Star: What is the ideal solution?
Constraints: What prevents us from getting there right now?
Compromises: How close can we reasonably get given these constraints?
One way to frame it is is that 2 & 3 are the product version of tech debt.[1]
It’s important to understand what constraints are fair game to ignore for 1 and which are not.
I often call these ephemeral or situational constraints.
They are constraints that are not fundamental to the product problem at hand,
but relate to the environment in which the product is being built and could be lifted or change over time.
Things like:
Engineering resources
Time
Technical limitations (within reason)
Performance
Backwards compatibility
Regulatory requirements
Unlike ephemeral constraints, certain requirements are part of the problem description and cannot be ignored.
Some examples from the case studies below:
Nearly every domain of human endeavor has a version of divide and conquer:
instead of solving a complex problem all at once, break it down into smaller, manageable components and solve them separately.
Product design is no different.
This process really shines when you’re dealing with the kinds of tough product problems where at least two of these questions are hard,
so breaking it down can do wonders for reducing complexity.
By solving these components separately,
our product design process becomes can more easily adapt to changes.
I have often seen “unimplementable” solutions become implementable down the line,
due to changes in internal or external factors, or simply because someone had a lightbulb moment.
By addressing these components separately, when constraints get lifted all we need to reevaluate is our compromises.
But without this modularization, our only solution is to go back to the drawing board.
Unsurprisingly, companies often choose to simply miss out on the opportunity, because it’s cheaper (or seems cheaper) to do so.
Every shipping goal is derived from the North Star, like peeling layers off an onion.
This is whether you realize it or not.
Whether you realize it or not, every shipping goal is always derived from the North Star, like peeling layers off an onion.
In some contexts the process of breaking down a bigger shipping goal into milestones that can ship independently is even called layering.
The process is so ingrained, so automatic, that most product designers don’t realize they are doing it.
They go from hovercar to car so quickly they barely realize the hovercar was there to begin with.
Thinking about the North Star is taboo — who has time for daydreaming?
We must ship, yesterday!
But the hovercar is fundamental.
Without it, there is no skateboard — you can’t reduce the unknown.
When designing it is not an explicit part of the process,
the result is that the main driver of all product design decisions is something that can never be explicitly discussed and debated like any other design decision.
In what universe is that efficient?
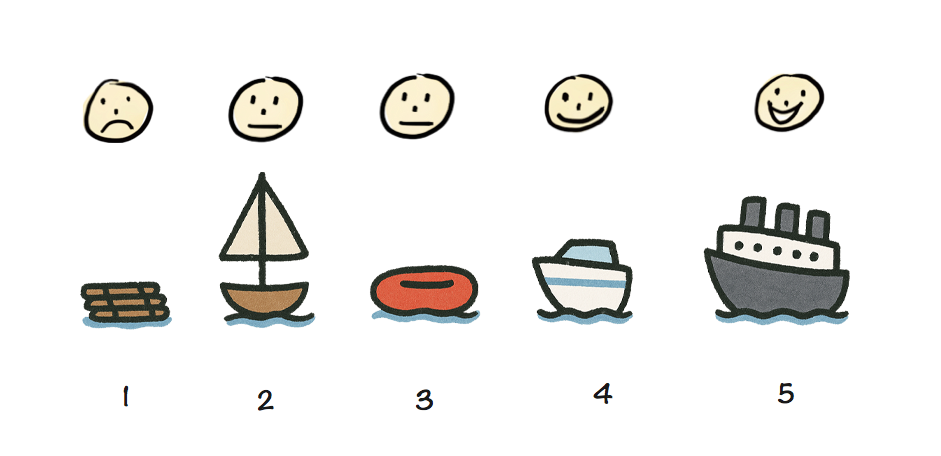
A skateboard might be a good MVP if your ultimate vision is a hovercar,
but it would be a terrible minimum viable cruise ship — you might want to try a wooden raft for that.
A skateboard may be a great MVP for a car, but a terrible MVP for a cruise ship.
Making the North Star taboo doesn’t make it disappear (when did that ever work?).
It just means that everyone is following a different version of it.
And since MVPs are products of the North Star, this will manifest as difficulty reaching consensus at every step of the way.
The product team will disagree on whether to ship a skateboard or a wooden raft,
then on whether to build a scooter or a simple sailboat,
then on whether to work on a speedboat or a yacht,
and so on.
It will seem like there is so much disconnect that every decision is hard,
but there is actually only one root disconnect that manifests as multiple because it is never addressed head on.
When the North Star is not clearly articulated, everyone has their own.
Here is a story that will sound familiar to many readers:
A product team is trying to design a feature to address a specific user pain point.
Alice has designed an elegant solution that addresses not just the problem at hand, but several prevalent longstanding user pain points at once — an eigensolution.
She is aware it would be a little trickier to implement than other potential solutions,
but the increase in implementation effort is very modest, and easily offset by the tremendous improvement in user experience.
She has even outlined a staged deployment strategy that allows it to ship incrementally, adding value and getting customer feedback earlier.
Excited, she presents her idea to the product team, only to hear engineering manager Bob dismiss it with “this is scope creep and way too much work, it’s not worth doing”.
However, what Bob is actually thinking is “this is a bad idea; any amount of work towards it is a waste”.
The design session is now derailed; instead of debating Alice’s idea on its merits, the discussion has shifted towards costing and/or reducing effort.
But this is a dead end because the amount of work was never the real problem.
In the end, Alice wants to be seen as a team player, so she backs off and concedes to Bob’s “simpler” idea, despite her worries that it is overfit to the very specific use case being discussed, and the product is now worse.
Arguing over effort feels safer and less confrontational than debating vision — but is often a proxy war.
Additionally, it is not productive.
If the idea is poor, effort is irrelevant.
And once we know an idea is good and believe it to our core, we have more incentive to figure out implementation,
which often proves to be easier than expected once properly investigated.
Explicitly fleshing out the Hovercar strips away the noise and brings clarity.
When we answer the questions above in order and reach consensus on the North Star before moving on to the compromises,
we know what is an actual design decision and what is a compromise driven by practical constraints.
Articulating these separately, allows us to discuss them separately.
It is very hard to evaluate tradeoffs collaboratively if you are not on the same page about what we are trading off and how much it’s worth.
You need both the cost and the benefit to do a cost-benefit analysis!
Additionally, fleshing the North Star out separately ensures that everyone is on the same page about what is being discussed.
All too often have I seen early design sessions where one person is discussing the skateboard,
another the bicycle, and a third one the hovercar,
no-one realizing that the reason they can’t reach consensus is that they are designing different things.
Conventional wisdom is that we strip down the North Star to an MVP, ship that, then iterate based on user input.
With that process, our actual vision never really gets evaluated and by the time we get to it, it has already changed tremendously.
But did you know you can actually get input from real users without writing a single line of code?
Believe it or not, you don’t need to wait until a UI is prototyped to user test it.
You can even user test a low-fi paper prototype or even a wireframe.
This is widely known in usability circles, yet somehow entirely unheard of outside the field.
The user tells you where they would click or tap on every step, and you mock the UI’s response by physically manipulating the prototype or showing them a wireframe of the next stage.
Obviously, this works better for some types of products than others.
It is notably hard to mock rich interactions or UIs with too many possible responses.
But when it does work, its Impact/Effort ratio is very high;
you get to see whether your core vision is on the right track,
and adjust your MVP accordingly.
It can be especially useful when there are different perspectives within a team about what the North Star might be,
or when the problem is so novel that every potential solution is low-confidence.
No-one’s product intuition is always right, and there is no point in evaluating compromises if it turns out that even the “perfect” solution was not actually all that great.
So far, we have discussed the merits of designing our North Star,
assuming we will never be able to ship it.
However, in many cases,
simply articulating what the North Star is can bring it within reach.
It’s not magic, just human psychology.
Once we have a North Star, we can use it to evaluate proposed solutions:
How do they relate to it?
Are they a milestone along a path that ends at the North Star?
Do they actively prevent us from ever getting there?
Prioritizing solutions that get us closer to the North Star can be a powerful momentum building tool.
Humans find it a lot easier to make one more step along a path they are already on, than to make the first step on an entirely new path.
This is well-established in psychology and often used as a technique for managing depression or executive dysfunction.
However, it applies on anything that involves humans — and that includes product design.
Once we’re partway there, it naturally begs the question: can we get closer? How much closer?
Even if we can’t get all the way there, maybe we can close enough that the remaining distance won’t matter.
And often, the closer you get, the more achievable the finish line gets.
In fact, sometimes simply reframing the North Star as a sequence of milestones rather than a binary goal can be all that is needed to make it feasible.
For an example of this, check out the CSS Nesting case study below.
In my 20 years of product design, I have seen ephemeral constraints melt away so many times I have learned to interpret “unimplementable” as “kinda hard; right now”.
Two examples from my own experience that I find particularly relevant below,
one around Survey UI, and one around a CSS language feature.
Originally, I needed to aggressively prioritize due to minimal engineering resources, which led me to design an extremely low-effort solution which still satisfied requirements.
The engineer hated the low-effort idea so much, he prototyped a much higher-effort solution in a day, backend and all.
Previously, this would have been entirely out of the question.
Once I took the ephemeral constraints out of the question, I was able to design a much better, novel solution, but it got pushback on the basis of effort.
Prototyping it allowed us to user test it, which revealed it performed way better than alternatives.
Once user testing built engineering momentum and the implementation was more deeply looked into, it turned out it did not actually require as much effort as initially thought.
Here is a dirty little secret about software engineering (and possibly any creative pursuit):
neither feasibility nor effort are fixed for a given task.
Engineers are not automatons that will implement everything with the same energy and enthusiasm.
They may implement product vision they disagree with,
but you will be getting very poor ROI out of their time.
Investing the time and energy to get engineers excited can really pay dividends.
When good engineers are excited, they become miracle workers.
In fact, engineering momentum is often, all that is needed to make the infeasible, feasible.
It may seem hard to fit this into the crunch of OKRs and KPIs but it’s worth it; the difference is not small, it is orders of magnitude.
Things that were impossible or insurmountable become feasible, and things that would normally take weeks or months get done in days.
One way to build engineering momentum is to demonstrate the value and utility of what is being built.
All too often, product decisions are made in a vacuum, based on gut feelings and assumptions about user needs.
Backing them up with data, such as usability testing sessions is an excellent way to demonstrate (and test!) their basis.
When possible, having engineers observe user testing sessions firsthand can be much more powerful than secondhand reports.
Example of CSS code, with (right) and without (left) nesting.
Which one is easier to read?
This is one of the rare cases where the North Star was well known in advance,
since the syntax was already well established in developer tooling (CSS preprocessors).
Instead, the big challenge was navigating the practical constraints,
since CSS implemented in browsers has different performance characteristics,
so a syntax that is feasible for tooling may be out of reach for a browser.
In this case, the North Star syntax had been ruled out by browser engineers due to prohibitive parsing performance [3],
so we had to design a different, more explicit syntax that could be parsed more efficiently.
At this point, it is important to note that CSS Nesting is a feature that is very heavily used once available.
Conciseness and readability are paramount,
especially when conciseness is the sole purpose of the feature in the first place!
Initial attempts for a syntax that satisfied these technical requirements introduced a lot of noise,
making the syntax tedious to write and noisy to read.
Even worse, these attempts were actively incompatible with the North Star syntax, as well as other parts of the language (namely, the @scope rule).
This meant that even if the North Star syntax became feasible later,
CSS would need to forever support syntax that would then have no purpose,
and would only exist as a wart from the past, just like HTML doctypes.
Once Google became very keen to ship Nesting (driven by State of CSS 2022, which showed it as the top missing CSS feature),
a small subset of the CSS Working Group, led by Elika Etemad and myself met to explore alternatives,
and produced four competing proposals.
The one that the group voted to adopt [4] was the one I designed explicitly to answer the question:
If the North Star syntax is out of the question right now, what is the largest subset of it that is feasible?
Once we got consensus on this intermediate syntax, I started exploring whether we could get any closer to the 🌟, even proposing an algorithm that would reduce the number of cases that required the slower parsing to essentially an edge case.
A few other WG members joined me, with my co-TAG member Peter Linss being most vocal.
This is a big advantage of North Star compatible designs: it is much easier to convince people to move a little further along on the path they are already on, than to move to a completely different path.
With a bit of luck, you may even find yourself implementing an “infeasible” North Star without even realizing it, one little step at a time.
We initially faced a lot of resistance from browser engineers, until eventually a brilliant Google engineer, Anders Ruud and his team experimented with variations of my proposed algorithm and actually closed in on a way to implement the North Star syntax in Chrome.
The rest, as they say, is history. 🌟
Hopefully by now you’re convinced about the value of investing time in reaching alignment on an explicit North Star that has buy-in from the entire product team.
A common misconception is that the North Star is a static goal that prevents you from adapting to new data, such as customer feedback.
But often, your North Star will change a lot over time, and that’s okay.
Having an initial destination does not take away your ability to course correct.
That’s not giving up, it’s adapting.
And yes, it’s true that many product teams do use a vision-led approach — they just start from the car, not the hovercar.
While that confers some of the benefits above, there is still an implicit reduction happening, because the hovercar is still there in the back of their mind.
Note that for this framework to be beneficial, it is important that everyone is on the same page and understands the steps, benefits, and goals of this approach.
Co-designing a North Star with a team that sees the process as a pointless thought experiment will only add friction and will not confer any of these benefits.
Also, this is a mindset that can only work when applied top-down.
If you are not a decision-maker at your place of work and leadership is not on board,
you will have a very hard time if you try to push this ad hoc, without first getting leadership buy-in.
You can try sending them a link to this blog post!
If this post resonated, please share your own case studies in the comments.
Or, if you decide to give this framework a try, I’d love to hear how it went!
for any Compilers geeks out there that want all the deets: it required potentially unbounded lookahead since there is no fixed number of tokens a parser can read and be able to tell the difference between a selector and a declaration. ↩︎
I set out to announce two components I wrote for displaying Bluesky likes and ended up ranting about the pain of building accessible, localizable web components in 2025. The components are still here, though — lucky you?
I’m old enough to remember the golden Web 2.0 era, when many of today’s big social media platforms grew up.
A simpler time, when the Web was much more extroverted.
It was common for websites to embed data from others (the peak of mashups),
and prominently feature widgets from various platforms to showcase a post’s likes or shares.
Especially Twitter was so ubiquitous that the number of Twitter shares was my primary metric for how much people were interested in a blog post I wrote.
Then, websites started progressively becoming walled gardens, guarding their data with more fervor than Gollum guarding the Precious.
Features disappeared or got locked behind API keys, ridiculous rate limits, expensive paywalls, and other restrictions.
Don’t get me wrong, I get it.
A lot of it was reactionary, a response to abuse — the usual reason we can’t have nice things.
And even when it was to stimulate profit — it is understandable that they want to monetize their platforms.
People gotta eat.
I was recently reading this interesting article by Salma Alam-Naylor.
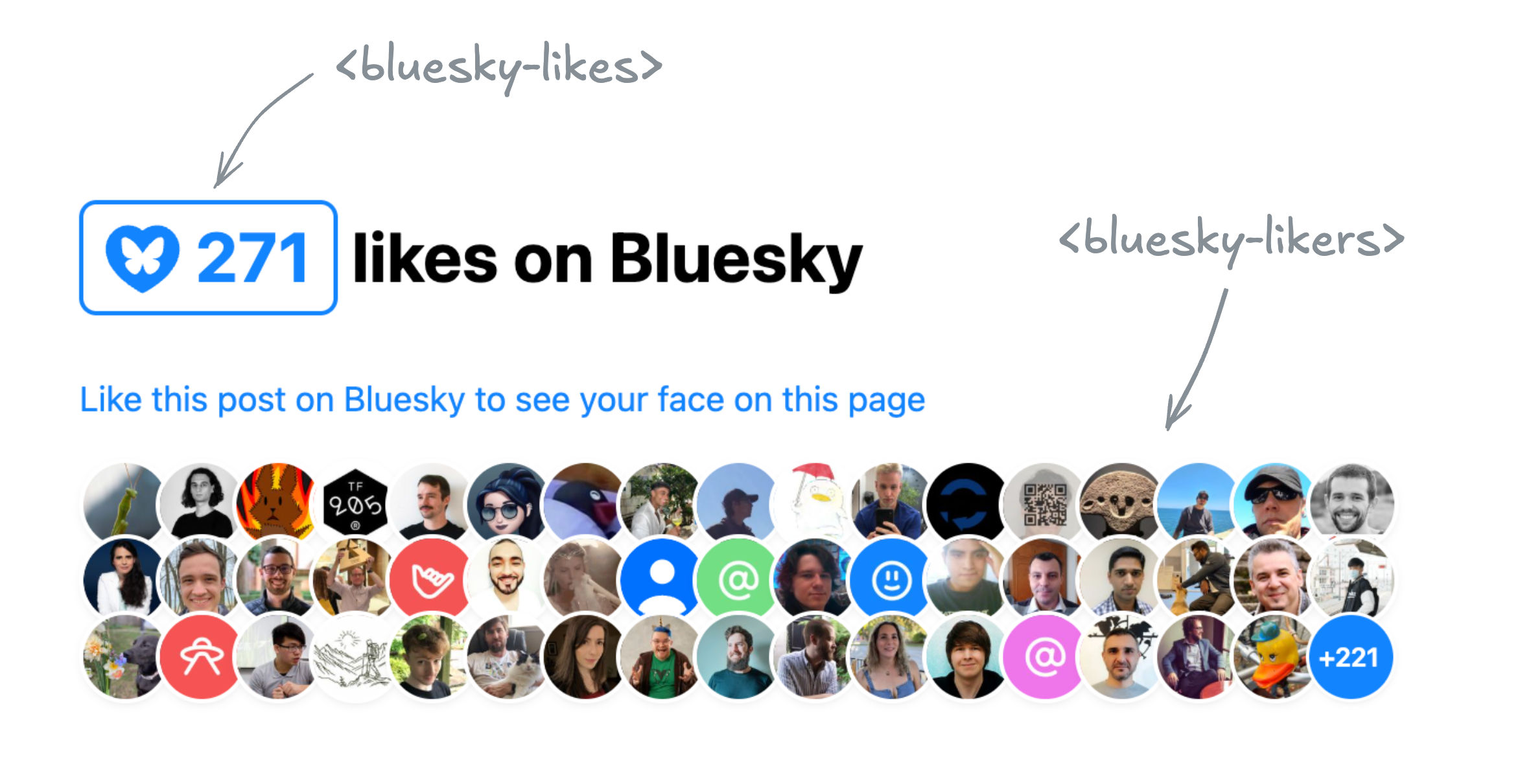
The article makes some great points, but it was something else that caught my eye: the widget of Bluesky likes at the bottom.
Salma's Bluesky likes widget that inspired these
I mentioned it to my trusty apprentice Dmitry who discovered the API was actually much simpler than what we’ve come to expect.
Later, it turned out Salma has even written an entire post on how to implement the same thing on your own site.
The openness of the API was so refreshing.
Not only can you read public data without being authenticated, you don’t even need an API key!
Major nostalgia vibes.
It seemed the perfect candidate for a web component that you can just drop in to a page, give it a post URL, and it will display the likes for that post.
I just had to make it, and of course use it right here.
“There is a lot of shame associated with backpedaling;
things like quitting your job, getting a divorce, or simply starting over are considered shameful.
But forward isn’t always progress.
And backward isn’t always regress.
Sometimes going down the wrong path isn’t a mistake —
it’s a construction line.”
It was exactly what I needed to hear.
You see, only a few days prior, Font Awesome and I had parted ways — the end of a short, but transformative chapter.
I’m proud of what we built together, and grateful for what I learned along the way.
But it was time to move on.
Jobs are a lot like relationships.
They often start with infatuation — and end with the realization that you’re simply not compatible, and that’s no-one’s fault.
Letting go always stings, even when it’s the right call.
There’s always grief: when you’re not ready to move on, you grieve the bond; when you are, you grieve your expectations.
But every ending leaves behind clarity — about who you are, and what makes you happy.
Today is my 39th birthday — and this summer marks 20 years since I first dipped my toes into this industry.
Naturally, I’ve been doing a lot of reflection.
I cannot count the number of times in my career I wished I could run JS in response to CSS property changes,
regardless of what triggered them: media queries, user actions, or even other JS.
Use cases abound.
Here are some of mine:
Implement higher level custom properties in components, where one custom property changes multiple others in nontrivial ways (e.g. a --variant: danger that sets 10 color tokens).
Polyfill missing CSS features
Change certain HTML attributes via CSS (hello --aria-expanded!)
Set CSS properties based on other CSS properties without having to mirror them as custom properties
The most recent time I needed this was to prototype an idea I had for Web Awesome,
and I decided this was it:
I’d either find a good, bulletproof solution, or I would build it myself.
The story of how a weird little UI to collect sentiment alongside survey responses defied constraints and triumphed over skepticism through usability testing.
One would think that we’ve more or less figured survey UI out by now.
Multiple choice questions, checkbox questions, matrix questions, dropdown questions, freeform textfields, numerical scales,
what more could one possibly need?!
And yet, every time Google sponsored me to lead one of the State Of … surveys, and especially the inaugural State of HTML 2023 Survey,
I kept hitting the same wall; I kept feeling that the established options for answering UIs were woefully inadequate for
balancing the collection good insights with minimal friction for end-users.
The State Of surveys used a completely custom survey infrastructure,
so I could often (but not always) convince engineering to implement new question UIs.
After joining Font Awesome, I somehow found myself leading yet another survey, despite swearing never to do this again. 🥲
Alas, building a custom survey UI was simply not an option in this case; I had to make do with the existing options out there [1], so I felt this kind of pain to my core once again.
So what are these cases where the existing answering UIs are inadequate, and how could better ones help?
I’m hoping this case study to be Part 1 of a series around how survey UI innovations can help balance tradeoffs between user experience and data quality, though this is definitely the one I’m most proud of, as it was such a bumpy ride, but it was all worth it in the end.
Unlike Devographics, surveys are not FA’s core business, so the Impact/Effort tradeoff simply wasn’t there for a custom UI, at least at this point in time. I ended up going with Tally, mainly due to the flexibility of its conditional logic and its support for code injection (which among other things, allowed me to use FA icons — a whopping 120 different ones!). ↩︎
Disclaimer: This post expresses my opinions, which do not necessarily reflect consensus by the whole Web Components community.
A blog post by Ryan Carniato
titled “Web Components Are Not the Future” has recently stirred a lot of controversy.
A few other JS framework authors pitched in, expressing frustration and disillusionment around Web Components.
Some Web Components folkswroterebuttals,
while others repeatedlytried to get to the bottom of the issues,
so they could be addressed in the future.
When you are on the receiving end of such an onslaught,
the initial reaction is to feel threatened and become defensive.
However, these kinds of posts can often end up shaking things up and pushing a technology forwards in the end.
I have some personal experience:
after I published my 2020 post titled “The failed promise of Web Components” which also made the rounds at the time,
I was approached by a bunch of folks (Justin Fagnani, Gray Norton, Kevin Schaaf) about teaming up to fix the issues I described.
The result of these brainstorming sessions was the Web Components CG which now has a life of its own
and has become a vibrant Web Components community that has helped move several specs of strategic importance forwards.
Today I start a new chapter in my career.
After a decade at MIT, teaching and
doing research at the intersection of usability and programming language design,
I wrapped up my PhD two weeks ago
(yes, I’m a Dr now! And damn right I will — once it actually sinks in)
and today I start my new role as Product Lead at Font Awesome.
I will be evaluating user needs and improving product design and usability across all company products,
with an emphasis on Web Awesome,
the product we are launching early next year to revolutionize how Web UIs are built by using web components and CSS in ways you’ve never seen before.
Beyond improving the products themselves (all of which include extensive free & open source versions),
part of my role will utilize my web standards experience to collect web platform pain points from across the company and translating them to new and existing web standards proposals.
Yes, I know, it’s a match made in heaven. 😍
There is even a small chance I may have been the first to create an icon font for use in a web UI via @font-face,
which would make it even more wonderfully poetic that I’m joining the company that has become synonymous with icon fonts on the Web.
However, it was not my MIT PhD that led me to this role,
but an email from Dave Gandy (creator & CEO of Font Awesome) about Color.js,
that turned into hours of chats,
and eventually a job offer for a role I could not refuse, one that was literally molded around my skills and interests.
The role is not the only reason I’m excited to join Font Awesome, though.
The company itself is a breath of fresh air:
open source friendly (as Dave says, “literally the only reason we have Pro versions is that we need to sustain this somehow” 😅),
already profitable (= no scrambling to meet VC demands by cramming AI features nobody wants into our products),
fully remote, huge emphasis on work-life balance,
and an interview process that did not feel like an interview — or even a process.
In fact, they did not even want to look at my resume (despite my efforts 🤣).
It is telling that in their 10 years of existence, not a single person has left the company, and they have never had to let anyone go.
Moreover, it bridges the best of both worlds: despite having existed for a decade,
branching out to new products[1] and markets gives it a startup-like energy and excitement.
I had been extremely selective in the job opportunities I pursued, so it took a while to find the perfect role.
Having ADHD (diagnosed only last year — I want to write a blog post about that too at some point),
I knew it was crucial to find a job I could be passionate about:
ADHD folks are unstoppable machines in jobs they love (I have literally built my career by directing my hyperfocus to things that are actually productive),
but struggle way more than neurotypicals in jobs they hate.
It took a while, but when I started talking with Dave, I knew Font Awesome was it.
I’m still reeling from the mad rush of spending the past couple of months averaging 100-hour weeks to wrap up my PhD before starting,
but I couldn’t be more excited about this new chapter.
I’m hoping to write a series of blog posts in the coming weeks about about my journey to this point.
Things like:
How I decided that academia was not for me — but persisted to the finish line anyway because I’m stubborn AF 😅
How I realized that product work is my real calling, not software engineering per se (as much as I love both)
How I used web technologies instead of LaTeX to write my PhD thesis (and print it to PDF for submission), with 11ty plus several open source plugins, many of which I wrote, an ecosystem I hope to one day free more people from the tyranny of LaTeX (which was amazing in the 70s, but its ergonomics are now showing their age).
But for now, I just wanted to share the news, and go off to make the web more awesome — for everyone. 🚀
A few days ago, I gave a very well received talk about API design at dotJS titled “API Design is UI Design” [1].
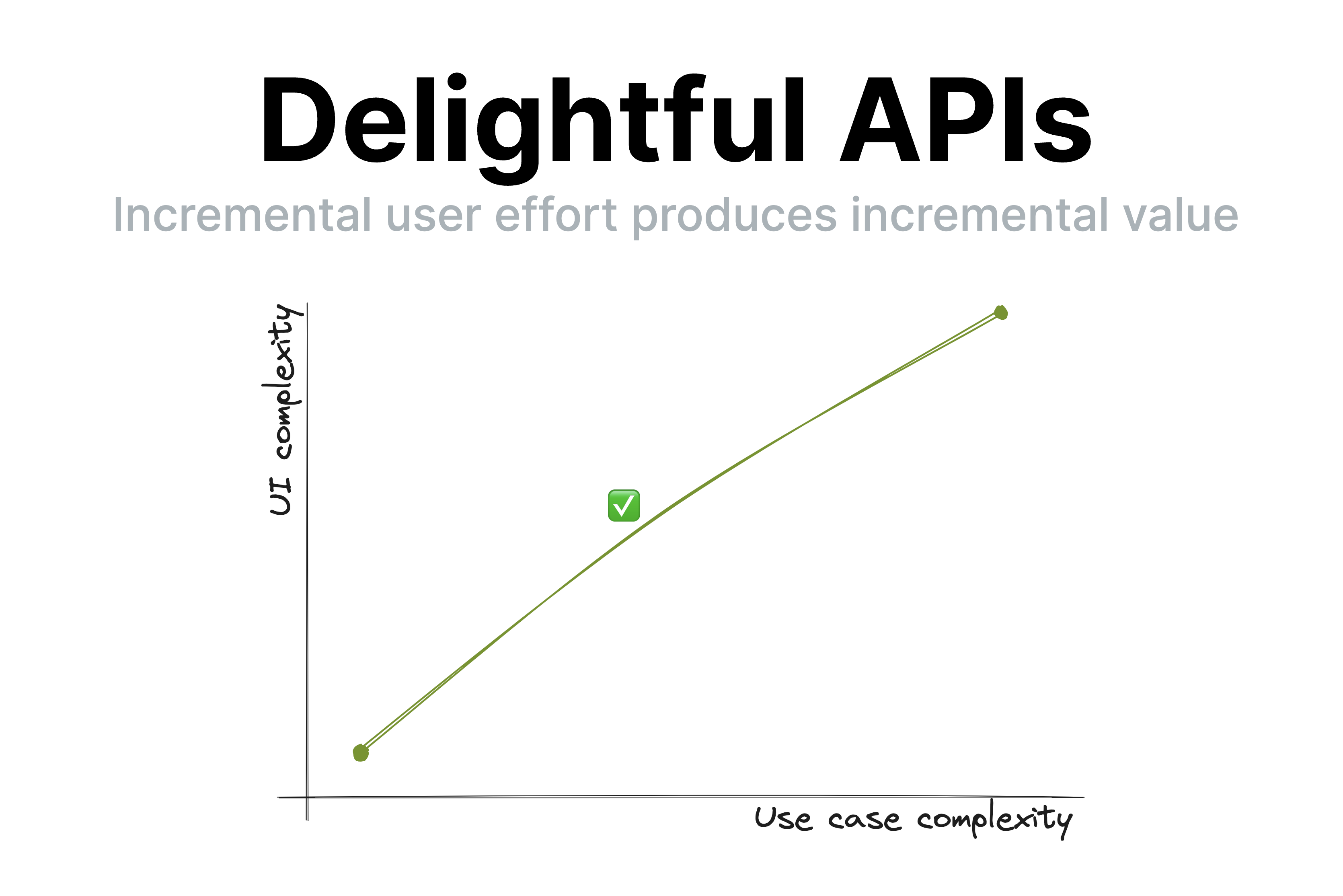
One of the points I made was that good UIs (and thus, good APIs) have a smooth UI complexity to Use case complexity curve.
This means that incremental user effort results in incremental value;
at no point going just a little bit further requires a disproportionately big chunk of upfront work [2].
Observing my daughter’s second ever piano lesson today made me realize how this principle extends to education and most other kinds of knowledge transfer (writing, presentations, etc.).
Her (generally wonderful) teacher spent 40 minutes teaching her notation, longer and shorter notes, practicing drawing clefs, etc.
Despite his playful demeanor and her general interest in the subject, she was clearly distracted by the end of it.
It’s easy to dismiss this as a 5 year old’s short attention span, but I could tell what was going on:
she did not understand why these were useful, nor how they connect to her end goal, which is to play music.
To her, notation was just an assortment of arbitrary symbols and lines, some of which she got to draw.
Note lengths were just isolated sounds with no connection to actual music.
Once I connected note lengths to songs she has sung with me and suggested they try something more hands on, her focus returned instantly.
I mentioned to her teacher that kids that age struggle to learn theory for that long without practicing it.
He agreed, and said that many kids are motivated to get through the theory because they’ve heard their teacher play nice music and want to get there too.
The thing is… sure, that’s motivating.
But as far as motivations go, it’s pretty weak.
Humans are animals, and animals don’t play the long game, or they would die.
We are programmed to optimize for quick, easy dopamine hits.
The farther into the future the reward, the more discipline it takes to stay motivated and put effort towards it.
This applies to all humans, but even more to kids and ADHD folks [3].
That’s why it’s so hard for teenagers to study so they can improve their career opportunities and why you struggle to eat well and exercise so you can be healthy and fit.
So how does this apply to knowledge transfer?
It highlights how essential it is for students to
a) understand why what they are learning is useful and
b)put it in practice ASAP.
You can’t retain information that is not connected to an obvious purpose [4] — your brain will treat it as noise and discard it.
The thing is, the more expert you are on a topic, the harder these are to do when conveying knowledge to others.
I get it. I’ve done it too.
First, the purpose of concepts feels obvious to you, so it’s easy to forget to articulate it.
You overestimate the student’s interest in the minutiae of your field of expertise.
Worse yet, so many concepts feel essential that you are convinced nothing is possible without learning them (or even if it is, it’s just not The Right Way™).
Looking back on some of my earlier CSS lectures, I’ve definitely been guilty of this.
As educators, it’s very tempting to say “they can’t possibly practice before understanding X, Y, Z, they must learn it properly”.
Except …they won’t.
At best they will skim over it until it’s time to practice, which is when the actual learning happens.
At worst, they will give up.
You will get much better retention if you frequently get them to see the value of their incremental imperfect knowledge
than by expecting a big upfront attention investment before they can reap the rewards.
There is another reason to avoid long chunks of upfront theory:
humans are goal oriented.
When we have a goal, we are far more motivated to absorb information that helps us towards that goal.
The value of the new information is clear, we are practicing it immediately, and it is already connected to other things we know.
This means that explaining things in context as they become relevant is infinitely better for retention and comprehension than explaining them upfront.
When knowledge is a solution to a problem the student is already facing, its purpose is clear, and it has already been filtered by relevance.
Furthermore, learning it provides immediate value and instant gratification: it explains what they are experiencing or helps them achieve an immediate goal.
Even if you don’t teach, this still applies to you.
I would go as far as to say it applies to every kind of knowledge transfer:
teaching, writing documentation, giving talks, even just explaining a tricky concept to your colleague over lunch break.
Literally any activity that involves interfacing with other humans benefits from empathy and understanding of human nature and its limitations.
To sum up:
Always explain why something is useful. Yes, even when it’s obvious to you.
Minimize the amount of knowledge you convey before the next opportunity to practice it.
For non-interactive forms of knowledge transfer (e.g. a book), this may mean showing an example,
whereas for interactive ones it could mean giving the student a small exercise or task.
Even in non-interactive forms, you can ask questions — the receiver will still pause and think what they would answer even if you are not there to hear it.
Prefer explaining in context rather than explaining upfront.
“Show, don’t tell”? Nah.
More like “Engage, don’t show”.
(In the interest of time, I’m posting this without citations to avoid going down the rabbit hole of trying to find the best source for each claim, especially since I believe they’re pretty uncontroversial in the psychology / cognitive science literature. That said, I’d love to add references if you have good ones!)
When it does, this is called a usability cliff. ↩︎
I often say that optimizing UX for people with ADHD actually creates delightful experiences even for those with neurotypical attention spans.
Just because you could focus your attention on something you don’t find interesting doesn’t mean you enjoy it.
Yet another case of accessibility helping everyone! ↩︎
I mean, you can memorize anything if you try hard enough, but by optimizing teaching we can keep rote memorization down to the bare minimum. ↩︎
The CSS WG resolved to add if() to CSS, but that won’t be in browsers for a while.
What are our options in the meantime?
A couple days ago, I posted about the recent CSS WG resolution to add an if() function to CSS.
Great as it may be, this is still a long way off, two years if everything goes super smoothly, more if not.
So what can you do when you need conditionals right now?
You may be pleased to find that you’re not completely out of luck.
There is a series of brilliant, horrible hacks that enable you to expose the kinds of higher level custom properties that conditionals typically enable.
The instinctive reaction many developers have when seeing hacks like these is “Nice hack, but can’t possibly ever use this in production”.
This sounds reasonable on the surface (keeping the codebase maintainable is a worthy goal!) but
when examined deeply, it reflects the wrong order of priorities,
prioritizing developer convenience over user convenience.
The TAG maintains a Web Platform Design Principles document [1]
that everyone designing APIs for the web platform is supposed to read and follow.
I’m a strong believer in having published Design Principles, for any product[2].
They help stay on track, and remember what the big picture vision is, which is otherwise easy to lose sight of in the day to day minutiae.
One of the core principles in the document is the Priority of Constituencies.
The core of it is:
User needs come before the needs of web page authors, which come before the needs of user agent implementors, which come before the needs of specification writers, which come before theoretical purity.
Obviously in most projects there are far fewer stakeholders than for the whole web platform,
but the spirit of the principle still applies:
the higher the abstraction, the higher priority the user needs.
Or, in other words, consumers above producers.
For a more relatable example, in a web app using a framework like e.g. Vue and several Vue components,
the user needs of website users come before the needs of the web app developers,
which come before the needs of the developers of its Vue components,
which come before the needs of the Vue framework developers (sorry Evan :).
The TAG did not invent this principle; it is well known in UX and Product circles with a number of different wordings:
“Put the pain on those who can bear it”
Prefer internal complexity over external complexity
Why is that? Several reasons:
It is far easier to change the implementation than to change the user-facing API, so it’s worth making sacrifices to keep it clean from the get go.
Most products have way more users than developers, so this minimizes collective pain.
Internal complexity can be managed far more easily, with tooling or even good comments.
Managing complexity internally localizes it and contains it better.
Once the underlying platform improves, only one codebase needs to be changed to reap the benefits.
The corollary is that if hacks allow you to expose a nicer API to component users, it may be worth the increase in internal complexity (to a degree).
Just make sure that part of the code is well commented, and keep track of it so you can return to it once the platform has evolved to not require a hack anymore.
Like all principles, this isn’t absolute.
A small gain in user convenience is not a good tradeoff when it requires tremendous implementation complexity.
But it’s a good north star to follow.
As to whether custom properties are a better option to control styling than e.g. attributes,
I listed several arguments for that in my previous article.
Although, there are also cases where using custom properties is not a good idea…
In a nutshell, when the abstraction is likely to leak.
Ugliness is only acceptable if it’s encapsulated and not exposed to component users.
If there is a high chance they may come into contact with it, it might be a better idea to simply use attributes and call it a day.
Example callouts with three variants.
In many of the examples below, I use variants as the canonical example of a custom property that a component may want to expose.
However, if component consumers may need to customize each variant, it may be better to use attributes so they can just use e.g. [variant="success"] instead of having to understand whatever crazy hack was used to expose a --variant custom property.
And even from a philosophical purity perspective, variants are on the brink of presentational vs semantic anyway.
There is a host of hacks and workarounds that people have come up with to make up for the lack of inline conditionals in CSS,
with the first ones dating back to as early as 2015.
However, instead of using this to map a range to another range,
we use it to map two points to two other points,
basically the two extremes of both ranges: and to select and respectively.
Back then, min() and max() were not available, so he had to divide each factor by an obscure constant to make it equal to 1 when it was not 0.
Once abs() ships this will be even simpler (the inner max() is basically getting the absolute value of N - var(--foo))
Ana Tudor also wrote about this in 2018, in this very visual article: DRY Switching with CSS Variables.
Pretty sure she was also using boolean algebra on these too (multiplication = AND, addition = OR), but I couldn’t find the exact post.
This was independently discovered by Ana Tudor (c. 2017),
Jane Ori in April 2020 (who gave it the name “Space Toggle”),
David Khoursid (aka David K Piano) in June 2020 (he called it prop-and-lock),
and yours truly in Oct 2020 (I called it the --var: ; hack, arguably the worst name of the three 😅).
The core idea is that var(--foo, fallback) is actually a very limited form of conditional: if --foo is initial (or IACVT), it falls back to fallback, otherwise it’s var(--foo).
Furthermore, we can set custom properties (or their fallbacks) to empty values to get them to be ignored when used as part of a property value.
It looks like this:
One of the downsides of this version is that it only supports two states per variable.
Note how we needed two variables for the two states.
Another downside is that there is no way to specify a fallback if none of the relevant variables are set.
In the example above, if neither --if-success nor --if-warning are set, the background declaration will be empty, and thus become IACVT which will make it transparent.
In 2023, Roma Komarov expanded the technique into what he called “Cyclic Dependency Space Toggles” which
addresses both limitations:
it supports any number of states,
and allows for a default value.
The core idea is that variables do not only become initial when they are not set, or are explicitly set to initial,
but also when cycles are encountered.
Roma’s technique depends on this behavior by producing cycles on all but one of the variables used for the values.
It looks like this:
A downside of this method is that since the values behind the --variant-success, --variant-warning, etc variables are specific to the --variant variable
they need to be namespaced to avoid clashes.
A big downside of most of these methods (except for the animation-based ones) is that you need to specify all values of the property in one place,
and the declaration gets applied whether your custom property has a value or not,
which makes it difficult to layer composable styles leading to some undesirable couplings.
Roma Komarov’s “Layered Toggles” method addresses this for some cases
by allowing us to decouple the different values by taking advantage of Cascade Layers.
The core idea is that Cascade Layers include a revert-layer keyword that will cause the current layer to be ignored wrt the declaration it’s used on.
Given that we can use unnamed layers, we can simply user a @layer {} rule for every block of properties we want to apply conditionally.
This approach does have some severe limitations which made it rather unpractical for my use cases.
The biggest one is that anything in a layer has lower priority than any unlayered styles,
which makes it prohibitive for many use cases.
Also, this doesn’t really simplify cyclic toggles, you still need to set all values in one place.
Still, worth a look as there are some use cases it can be helpful for.
The core idea behind this method is that paused animations (animation-play-state: paused) can still be advanced by setting animation-delay to a negative value.
For example in an animation like animation: 100s foo, you can access the 50% mark by setting animation-delay: -50s.
It’s trivial to transform raw numbers to <time> values, so this can be abstracted to plain numbers for the user-facing API.
Here is a simple example to illustrate how this works:
This is merely to illustrate the core idea, having a --variant property that takes numbers is not a good API!
Though the numbers could be aliased to variables, so that users would set --variant: var(--success).
This technique seems to have been first documented by me in 2015, during a talk about …pie charts
(I would swear I showed it in an earlier talk but I cannot find it).
I never bothered writing about it, but someone else did, 4 years later.
To ensure you don’t get slightly interpolated values due to precision issues, you could also slap a steps() in there:
This is especially useful when 100 divided by your number of values produces repeating decimals,
e.g. 3 steps means your keyframes are at increments of 33.33333%.
A benefit of this method is that defining each state is done with regular declarations, not involving any weirdness,
and that .
It does also have some obvious downsides:
Values restricted to numbers
Takes over the animation property, so you can’t use it for actual animations.
So far all of these methods impose constraints on the API exposed by these custom properties:
numbers by the linear interpolation method and weird values that have to be hidden behind variables
for the space toggle and cyclic toggle methods.
In October 2022, Jane Ori was the first one to discover a method that actually allows us to support plain keywords,
which is what the majority of these use cases needs.
She called it “CSS-Only Type Grinding”.
Its core idea is if a custom property is registered (via either @property or CSS.registerProperty()),
assigning values to it that are not valid for its syntax makes it IACVT (Invalid at computed value time) and it falls back to its initial (or inherited) value.
She takes advantage of that to progressively transform keywords to other keywords or numbers through a series of intermediate registered custom properties,
each substituting one more value for another.
I was recently independently experimenting with a similar idea.
It started from a use case of one of my components where I wanted to implement a --size property with two values: normal and large.
Style queries could almost get me there, but I also needed to set flex-flow: column on the element itself when --size was large.
The end result takes N + 1 @property rules, where N is the number of distinct values you need to support.
The first one is the rule defining the syntax of your actual property:
We can also transform keywords to numbers, by replacing successive keywords with <integer> in the syntax, one at a time, with different initial values each time.
Here is the --variant example using this method:
In 2018, Roma Komarov discovered another method that allows plain keywords to be used as the custom property API,
forgot about it, then rediscovered it in June 2023 😅.
He still never wrote about it, so these codepens are the only documentation we have.
It’s a variation of the previous method: instead of using a single @keyframes rule and switching between them via animation-delay,
define several separate @keyframes rules, each named after the keyword we want to use:
Every one of these methods has limitations, some of which are inerent in its nature, but others can be improved upon.
In this section I will discuss some improvements that me or others have thought of.
I decided to include these in a separate section, since they affect more than one method.
A big downside with the animation-based approaches (3 and 5) is the place of animations in the cascade:
properties applied via animation keyframes can only be overridden via other animations or !important.
One way to deal with that is to set custom properties in the animation keyframes, that you apply in regular rules.
To use the example from Variable animation name:
Note that you can combine the two approaches (variable animation-name and paused animations)
when you have two custom properties where each state of the first corresponds to N distinct states of the latter.
For example, a --variant that sets colors, and a light/dark mode within each variant that sets different colors.
Another downside of the animation-based approaches is that they take over the animation property.
If authors want to apply an animation to your component, suddenly a bunch of unrelated things stop working, which is not great user experience.
There isn’t that much to do here to prevent this experience, but you can at least offer a way out:
instead of defining your animations directly on animation, define them on a custom property, e.g. --core-animations.
Then, if authors want to apply their own animations, they just make sure to also include var(--core-animations) before or after.
Many of the approaches above are based on numerical values, which are then mapped to the value we actually want.
For numbers or dimensions, this is easy.
But what about colors?
I linked to Noah Liebman’s post above on recursive color-mix(),
where he presents a rather complex method to select among a continuous color scale based on a 0-1 number.
However, if you don’t care about any intermediate colors and just want to select among a few discrete colors, the method can be a lot simpler.
Simple enough to be specified inline.
Let me explain: Since color-mix() only takes two colors, we need to nest them to select among more than 2, no way around that.
However, the percentages we calculate can be very simple: 100% when we want to select the first color and 0% otherwise.
I plugged these numbers into my CSS range mapping tool
(example) and noticed a pattern:
If we want to output 100% when our variable (e.g. --variant-index) is N-1 and 0% when it’s N, we can use 100% * (N - var(--variant-index)).
And here is a more realistic one, using the Type Grinding method to transform keywords to numbers, and then using the above technique to select among 4 colors for backgrounds and borders (codepen).
There are two components to each method: the input values it supports, i.e. your custom property API that you will expose, e.g. numbers, keywords, etc.,
and the output values it supports (<dimension>, keywords, etc.).
If we can transform the input values of one method to the input values of another, we can mix and match approaches to maximize flexibility.
For example, we can use type grinding to transform keywords to numbers, and then use paused animations or binary linear interpolation to select among a number of quantitative values based on that number.
Keywords → Numbers
Type grinding
Numbers → Keywords
We can use paused animations to select among a number of keywords based on a number (which we transform to a negative animation-delay).
Impractical outside of Shadow DOM due to name clashes
Takes over animation property
Cascade weirdness
The most important consideration is the API we want to expose to component users.
After all, exposing a nicer API is the whole point of this, right?
If your custom property makes sense as a number without degrading usability
(e.g. --size may make sense as a number, but small | medium | large is still better than 0 | 1 | 2),
then Binary Linear Interpolation is probably the most flexible method to start with,
and as we have seen in Combining approaches section, numbers can be converted to inputs for every other method.
Between the two, Type Grinding is the one providing the best encapsulation,
since it relies entirely on custom properties and does not hijack any native properties.
Unfortunately, the fact that @property is not yet supported in Shadow DOM throws a spanner in the works,
but since these intermediate properties are only used for internal calculations,
we can just give them obscure names and insert them in the light DOM.
Phew! That was a long one. If you’re aware of any other techniques, let me know so I can add them.
And I think after all of this, if you had any doubt that we need if() in CSS,
the sheer number and horribleness of these hacks must have dispelled it by now. 😅
Thanks to Roma Komarov for reviewing earlier drafts of this article.
I’ve always thought this was our most important deliverable, and pushed for prioritizing it. Recently, I even became editor of it. 🙃 ↩︎
I’m using product here in the general sense, of any software product, technology, or API, not just for-profit or commercial ones. ↩︎
Last week, the CSS WG resolved to add an inline if() to CSS.
But what does that mean, and why is it exciting?
Last week, we had a CSS WG face-to-face meeting in A Coruña, Spain.
There is one resolution from that meeting that I’m particularly excited about:
the consensus to add an inline if() to CSS.
While I was not the first to propose an inline conditional syntax,
I did try and scope down the various nonterminating discussions into an MVP that can actually be implemented quickly,
discussed ideas with implemenators,
and eventually published a concrete proposal and pushed for group resolution.
Quite poetically, the relevant discussion occurred on my birthday, so in a way, I got if() as the most unique birthday present ever. 😀
This also comes to show that proposals being rejected is not the end-all for a given feature.
It is in fact quite common for features to be rejected for several times before they are accepted: CSS Nesting, :has(), container queries were all simply the last iteration in a series of rejected proposals.
if() itself was apparently rejected in 2018 with very similar syntax to what I proposed.
What was the difference? Style queries had already shipped, and we could simply reference the same syntax for conditions (plus media() and supports() from Tab’s @when proposal) whereas in the 2018 proposal how conditions would work was largely undefined.
I posted about this on a variety of social media, and the response by developers has been overwhelmingly positive:
I even had friends from big companies writing to tell me their internal Slacks blew up about it.
This proves what I’ve always suspected, and was part of the case I made to the CSS WG: that this is a huge pain point.
Hopefully the amount and intensity of positive reactions will help browsers prioritize this feature and add it to their roadmaps earlier rather than later.
Across all these platforms, besides the “I can’t wait for this to ship!” sentiment being most common,
there were a few other recurring questions and a fair bit of confusion that I figured were worth addressing.
Can we emulate the upcoming CSS contrast-color() function via CSS features that have already widely shipped?
And if so, what are the tradeoffs involved and how to best balance them?
Out of all the CSS features I have designed,
Relative Colors aka Relative Color Syntax (RCS) is definitely among the ones I’m most proud of.
In a nutshell, they allow CSS authors to derive a new color from an existing color value by doing arbitrary math on color components
in any supported color space:
--color-lighter: hsl(from var(--color) h s calc(l * 1.2));
--color-lighterer: oklch(from var(--color) calc(l + 0.2) c h);
--color-alpha-50: oklab(from var(--color) l a b / 50%);
The elevator pitch was that by allowing lower level operations they provide authors flexibility on how to derive color variations,
giving us more time to figure out what the appropriate higher level primitives should be.
Even if my prediction is off, it already is available to 83% of users worldwide,
and if you sort its caniuse page by usage,
you will see the vast majority of the remaining 17% doesn’t come from Firefox,
but from older Chrome and Safari versions.
I think its current market share warrants production use today,
as long as we use @supports to make sure things work in non-supporting browsers, even if less pretty.
Most Relative Colors tutorials
revolve around its primary driving use cases:
making tints and shades or other color variations by tweaking a specific color component up or down,
and/or overriding a color component with a fixed value,
like the example above.
While this does address some very common pain points,
it is merely scratching the surface of what RCS enables.
This article explores a more advanced use case, with the hope that it will spark more creative uses of RCS in the wild.
One of the big longstanding CSS pain points is that it’s impossible to automatically specify a text color that is guaranteed to be readable on arbitrary backgrounds,
e.g. white on darker colors and black on lighter ones.
Why would one need that?
The primary use case is when colors are outside the CSS author’s control.
This includes:
User-defined colors. An example you’re likely familiar with: GitHub labels. Think of how you select an arbitrary color when creating a label and GitHub automatically picks the text color — often poorly (we’ll see why in a bit)
Colors defined by another developer. E.g. you’re writing a web component that supports certain CSS variables for styling.
You could require separate variables for the text and background, but that reduces the usability of your web component by making it more of a hassle to use.
Wouldn’t it be great if it could just use a sensible default, that you can, but rarely need to override?
GitHub Labels are an example where colors are user-defined, and the UI needs to pick a text color that works with them.
GitHub uses WCAG 2.1 to determine the text color, which is why (as we will see in the next section) the results are often poor.
Even in a codebase where every line of CSS code is controlled by a single author,
reducing couplings can improve modularity and facilitate code reuse.
The good news is that this is not going to be a pain point for much longer.
The CSS function contrast-color() was designed to address exactly that.
This is not new, you may have heard of it as color-contrast() before, an earlier name.
I recently drove consensus to scope it down to an MVP that addresses the most prominent pain points and can actually ship soonish,
as it circumvents some very difficult design decisions that had caused the full-blown feature to stall.
I then added it to the spec per WG resolution, though some details still need to be ironed out.
Glorious, isn’t it?
Of course, soonish in spec years is still, well, years.
As a data point, you can see in my past spec work that with a bit of luck (and browser interest), it can take as little as 2 years to get a feature shipped across all major browsers after it’s been specced.
When the standards work is also well-funded,
there have even been cases where a feature went from conception to baseline in 2 years,
with Cascade Layers being the poster child for this:
proposal by Miriam in Oct 2019,
shipped in every major browser by Mar 2022.
But 2 years is still a long time (and there are no guarantees it won’t be longer).
What is our recourse until then?
As you may have guessed from the title, the answer is yes.
It may not be pretty, but there is a way to emulate contrast-color() (or something close to it) using Relative Colors.
In the following we will use the OKLCh color space, which is the most perceptually uniformpolar color space that CSS supports.
Let’s assume there is a Lightness value above which black text is guaranteed to be readable regardless of the chroma and hue,
and below which white text is guaranteed to be readable.
We will validate that assumption later, but for now let’s take it for granted.
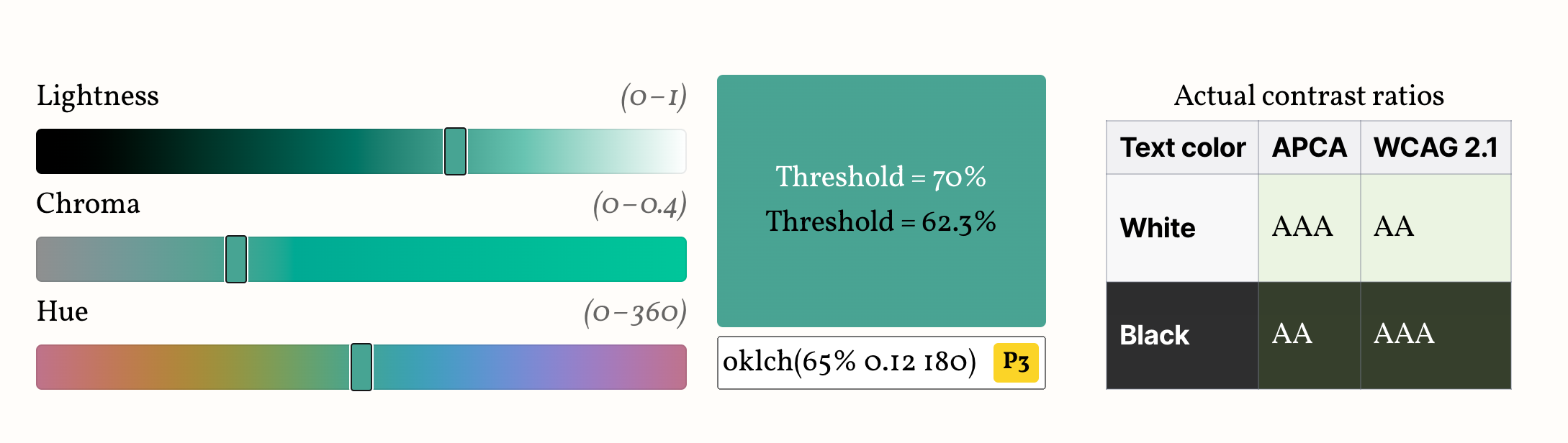
In the rest of this article, we’ll call that value the threshold and represent it as Lthreshold.
We will compute this value more rigously in the next section (and prove that it actually exists!),
but for now let’s use 0.7 (70%).
We can assign it to a variable to make it easier to tweak:
--l-threshold: 0.7;
Let’s work backwards from the desired result.
We want to come up with an expression that is composed of widely supported CSS math functions,
and will return 1 if L ≤ Lthreshold and 0 otherwise.
If we could write such an expression, we could then use that value as the lightness of a new color:
--l: /* ??? */;
color: oklch(var(--l) 0 0);
How could we simplify the task?
One way is to relax what our expression needs to return.
We don’t actually need an exact 0 or 1
If we can manage to find an expression that will give us 0 when L > Lthreshold
and > 1 when L ≤ Lthreshold,
we can just use clamp(0, /* expression */, 1) to get the desired result.
One idea would be to use ratios, as they have this nice property where they are > 1 if the numerator is larger than the denominator and ≤ 1 otherwise.
The ratio of is < 1 for L ≤ Lthreshold and > 1 when L > Lthreshold.
This means that will be a negative number for L < Lthreshold and a positive one for L > Lthreshold.
Then all we need to do is multiply that expression by a huge (in magnitude) negative number so that when it’s negative the result is guaranteed to be over 1.
One worry might be that if L gets close enough to the threshold we could get a number between 0 - 1,
but in my experiments this never happened, presumably since precision is finite.
The last piece of the puzzle is to provide a fallback for browsers that don’t support RCS.
We can use @supports with any color property and any relative color value as the test, e.g.:
In the previous section we’ve made a pretty big assumption:
That there is a Lightness value (Lthreshold) above which black text is guaranteed to be readable regardless of the chroma and hue,
and below which white text is guaranteed to be readable regardless of the chroma and hue.
But does such a value exist?
It is time to put this claim to the test.
When people first hear about perceptually uniform color spaces like Lab, LCH or their improved versions, OkLab and OKLCH,
they imagine that they can infer the contrast between two colors by simply comparing their L(ightness) values.
This is unfortunately not true, as contrast depends on more factors than perceptual lightness.
However, there is certainly significant correlation between Lightness values and contrast.
At this point, I should point out that while most web designers are aware of the WCAG 2.1 contrast algorithm,
which is part of the Web Content Accessibility Guidelines and baked into law in many countries,
it has been known for years that it produces extremely poor results.
So bad in fact that in some tests it performs almost as bad as random chance for any color that is not very light or very dark.
There is a newer contrast algorithm, APCA that produces far better results,
but is not yet part of any standard or legislation, and there have previously been some bumps along the way with making it freely available to the public (which seem to be largely resolved).
Some text
Some text
Which of the two seems more readable?
You may be surprised to find that the white text version fails WCAG 2.1,
while the black text version even passes WCAG AAA!
So where does that leave web authors?
In quite a predicament as it turns out.
It seems that the best way to create accessible color pairings right now is a two step process:
Use APCA to ensure actual readability
Compliance failsafe: Ensure the result does not actively fail WCAG 2.1.
I ran some quick experiments using Color.js
where I iterate over the OKLCh reference range (loosely based on the P3 gamut)
in increments of increasing granularity and calculate the lightness ranges for colors where white was the “best” text color (= produced higher contrast than black) and vice versa.
I also compute the brackets for each level (fail, AA, AAA, AAA+) for both APCA and WCAG.
I then turned my exploration into an interactive playground where you can run the same experiments yourself,
potentially with narrower ranges that fit your use case, or with higher granularity.
Calculating lightness ranges and contrast brackets for black and white on different background colors.
Note that these are the min and max L values for each level.
E.g. the fact that white text can fail WCAG when L ∈ [62.4%, 100%] doesn’t mean that every color with L > 62.4% will fail WCAG,
just that some do.
So, we can only draw meaningful conclusions by inverting the logic:
Since all white text failures are have an L ∈ [62.4%, 100%],
it logically follows that if L < 62.4%, white text will pass WCAG
regardless of what the color is.
By applying this logic to all ranges, we can draw similar guarantees for many of these brackets:
0% to 52.7%
52.7% to 62.4%
62.4% to 66.1%
66.1% to 68.7%
68.7% to 71.6%
71.6% to 75.2%
75.2% to 100%
Compliance WCAG 2.1
white
✅ AA
✅ AA
black
✅ AA
✅ AAA
✅ AAA
✅ AAA
✅ AAA
✅ AAA+
Readability APCA
white
😍 Best
😍 Best
😍 Best
🙂 OK
🙂 OK
black
🙂 OK
🙂 OK
😍 Best
Contrast guarantees we can infer for black and white text over arbitrary colors.
OK = passes but is not necessarily best.
You may have noticed that in general, WCAG has a lot of false negatives around white text,
and tends to place the Lightness threshold much lower than APCA.
This is a known issue with the WCAG algorithm.
Therefore, to best balance readability and compliance, we should use the highest threshold we can get away with.
This means:
If passing WCAG is a requirement, the highest threshold we can use is 62.3%.
If actual readability is our only concern, we can safely ignore WCAG and pick a threshold somewhere between 68.7% and 71.6%, e.g. 70%.
Here’s a demo so you can see how they both play out.
Edit the color below to see how the two thresholds work in practice, and compare with the actual contrast brackets, shown on the table next to (or below) the color picker.
Your browser does not support Relative Color Syntax, so the demo below will not work.
This is what it looks like in a supporting browser:
Lthreshold = 70%
Lthreshold = 62.3%
Actual contrast ratios
Text color
APCA
WCAG 2.1
White
Black
Avoid colors marked “P3+”, “PP” or “PP+”, as these are almost certainly outside your screen gamut,
and browsers currently do not gamut map properly, so the visual result will be off.
Note that if your actual color is more constrained (e.g. a subset of hues or chromas or a specific gamut),
you might be able to balance these tradeoffs better by using a different threshold.
Run the experiment yourself with your actual range of colors and find out!
Here are some examples of narrower ranges I have tried and the highest threshold that still passes WCAG 2.1:
It is particularly interesting that the threshold is improved to 64.5% by just ignoring colors that are not actually displayable on modern screens.
So, assuming (though sadly this is not an assumption that currently holds true) that browsers prioritize preserving lightness when gamut mapping, we could use 64.5% and still guarantee WCAG compliance.
You can even turn this into a utility class that you can combine with different thesholds:
This is only a start.
I can imagine many directions for improvement such as:
Since RCS allows us to do math with any of the color components
in any color space, I wonder if there is a better formula that still be implemented in CSS and balances readability and compliance even better.
E.g. I’ve had some chats with Andrew Somers (creator of APCA) right before publishing this,
which suggest that doing math on luminance (the Y component of XYZ) instead could be a promising direction.
We currently only calculate thresholds for white and black text.
However, in real designs, we rarely want pure black text,
which is why contrast-color() only guarantees a “very light or very dark color” unless the max keyword is used.
How would this extend to darker tints of the background color?
As often happens, after publishing this blog post, a ton of folks reached out to share all sorts of related work in the space.
I thought I’d share some of the most interesting findings here.
When colors have sufficiently different lightness values (as happens with white or black text),
humans disregard chromatic contrast (the contrast that hue/colorfulness provide)
and basically only use lightness contrast to determine readability.
This is why L can be such a good predictor of whether white or black text works best.
Another measure, luminance, is basically the color’s Y component in the XYZ color space,
and a good threshold for flipping to black text is when Y > 0.36.
This gives us another method for computing a text color:
As you can see in this demo by Lloyd Kupchanko, using Ythreshold > 36%
very closely predicts the best text color as determined by APCA.
In my tests (codepen) it appeared to work as well as the Lthreshold method,
i.e. it was a struggle to find colors where they disagree.
However, after this blog post, Lloyd added various Lthreshold boundaries to his demo,
and it appears that indeed, Lthreshold has a wider range where it disagrees with APCA than Ythreshold does.
Given this, my recommendation would be to use the Ythreshold method if you need to flip between black and white text,
and the Lthreshold method if you need to customize the text color further (e.g. have a very dark color instead of black).
About a week after publishing this post, I discovered a browser bug with color-mix() and RCS,
where colors defined via color-mix() used in from render RCS invalid.
You can use this testcase to see if a given browser is affected.
This has been fixed in Chrome 125 and Safari TP release 194, but it certainly throws a spanner in the works since the whole point of using this technique is that we don’t have to care how the color was defined.
There are two ways to work around this:
Adjust the @supports condition to use color-mix(), like so:
@supports (color: oklch(from color-mix(in oklch, red, tan) l c h)) {
/* ... */
}
The downside is that right now, this would restrict the set of browsers this works in to a teeny tiny set.
2. Register the custom property that contains the color:
This completely fixes it, since if the property is registered, by the time the color hits RCS, it’s just a resolved color value.
@property is currently supported by a much wider set of browsers than RCS, so this workaround doesn’t hurt compatiblity at all.
tl;dr:Overfitting happens when solutions don’t generalize sufficiently and is a hallmark of poor design.
Eigensolutions are the opposite: solutions that generalize so much they expose links between seemingly unrelated use cases.
Designing eigensolutions takes a mindset shift from linear design to composability.
Usability and aesthetics usually go hand in hand.
In fact, there is even what we call the “Aesthetic Usability Effect”:
users perceive beautiful interfaces as easier to use and cut them more slack when it comes to minor usability issues.
Unfortunately, sometimes usability and aesthetics can be at odds, also known as “form over function”.
A common incarnation of form-over-function, is when designers start identifying signifiers and affordances as noise to be eliminated,
sacrificing a great deal of learnability for an — often marginal — improvement in aesthetics.
Aesthetic and Minimalist Design is one of the Nielsen/Norman core usability heuristics (and all other heuristics taxonomies have something similar).
More poetically, Antoine de Saint-Exupéry said “Perfection is achieved, not when there is nothing more to add, but when there is nothing left to take away”.
However, this is one of those cases where everyone agrees with the theory, but the devil is in the details (though user testing can do wonders for consensus).